Hey there! Today, we’re diving into creating a cool rag (retrieval-augmented generation) app. Sometimes our app gives us chunks of text that don’t quite match up from our vector database. No worries, though! We’ve got a plan to fix it using Cohere’s platform API to re-rank our results.
Here’s our game plan:
- Starting Point: We’ll start by grabbing info from PDFs, and we’ll use Langchain to help us split those docs apart.
- Getting Fancy with Embeddings: Then, we’ll use ollama free embeddings to turn our text into fancy embeddings.
- Database Magic: Pinecone’s Vector Database will help us keep track of everything smoothly.
- Re-Ranking: With Cohere’s API, we’ll tweak our results to make them better.
- Accessing LLMs for Free: We’re also using Groq API to access LLMs (large language models) for free. That’s right, no cost!
- Testing, Testing: Finally, we’ll test everything with some question answering to make sure it’s all working like a charm.
So, let’s get started and make our rag app top-notch!
I am using jupyter notebook for this case you can use any editor or notebook. I have demo.pdf file in the same folder where i have created my notebook.
Let first grab all required api keys,
Pinecone
Go to https://app.pinecone.io and create api key.
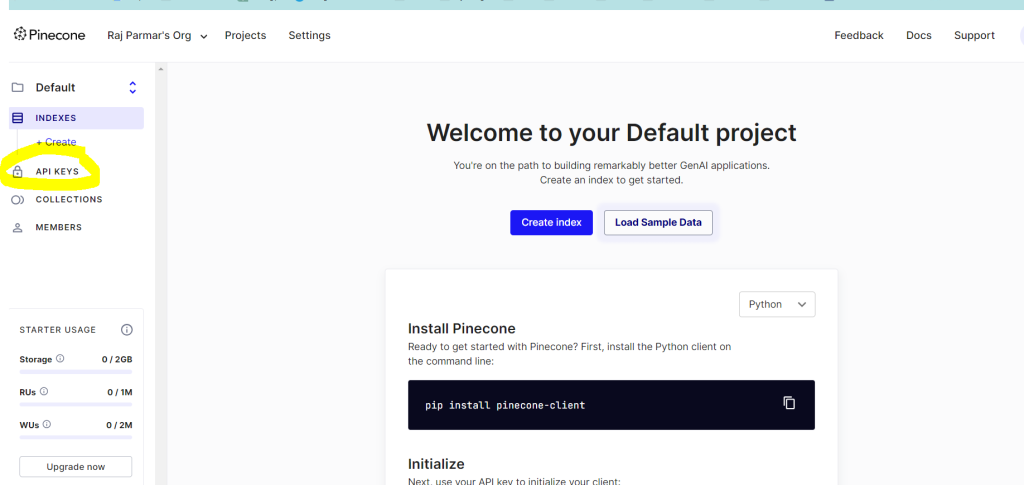
After creating api key store in env.py file from where you will take it. Then create index in pinecone.
Add index name, dimentions(taking 768), capacity mode take default serverless(which is in public review phase) and create with other default options. it will look like below,
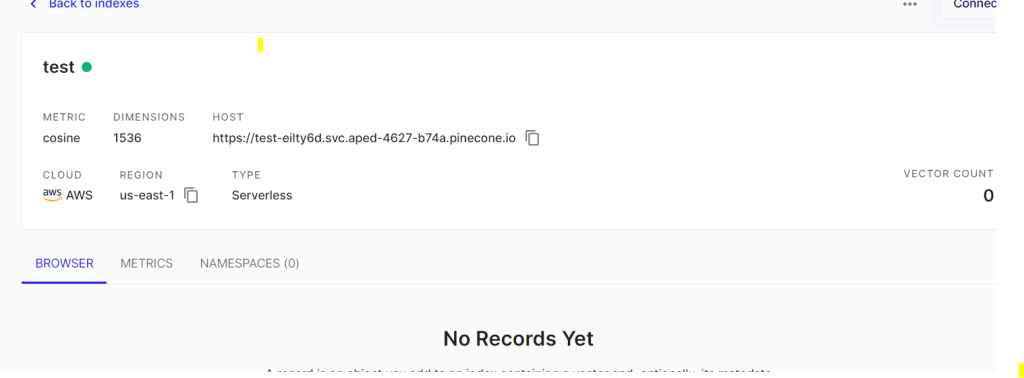
Groq
for groq api key go to groqcloud(https://console.groq.com/) , create account and create api key and store in env.py file.
for cohere go to https://dashboard.cohere.com/ and create account and create api key and store in env.py file.
Ollama
For ollama embedding we have to download ollama in our system and pull embedding model. refer https://medium.com/@gabrielrodewald/running-models-with-ollama-step-by-step-60b6f6125807 for this setup.
Now below is the code…
import PyPDF2
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_groq import ChatGroq
from env import groq_api_key,pinecone_api_key,cohere_api_key
llm_local = ChatOllama(model="mistral:instruct")
llm_groq = ChatGroq(
groq_api_key=groq_api_key,
#model_name='llama2-70b-4096'
model_name='mixtral-8x7b-32768'
)
# Read the PDF file
pdf = PyPDF2.PdfReader("demo.pdf")
pdf_text = ""
for page in pdf.pages:
pdf_text += page.extract_text()
# Split the text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_text(pdf_text)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
r1 = embeddings.embed_documents(
texts
)
import pinecone
from pinecone import Pinecone, ServerlessSpec
pc = Pinecone(api_key=pinecone_api_key)
pc.create_index(
name="testv1",
dimension=768,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
index = pc.Index("testv1")
for i in range(len(texts)):
index.upsert([((str(i),r1[i],{"text":texts[i]}))])
print("done upserting...")
def get_query_embdedding(text):
embedding=embeddings.embed_query(text)
return embedding
import cohere
# init client
co = cohere.Client(cohere_api_key)
query="when chandrayan landed on moon surface?"
question_embedding=get_query_embdedding(query)
query_result = index.query(vector=question_embedding, top_k=5, include_metadata=True)
similar_texts = []
# Extract metadata from query result
docs = {x["metadata"]['text']: i for i, x in enumerate(query_result["matches"])}
# Rerank the documents
rerank_docs = co.rerank(
model="rerank-english-v3.0",
query=query,
documents=list(docs.keys()),
top_n=5,
return_documents=True
)
# print("rerank_docs...",rerank_docs)
# Extract reranked documents
reranked_texts = [doc.document.text for doc in rerank_docs.results]
reranked_texts
context=" ".join(reranked_texts)
Template = f"Based on the following context : {context} generate precise summary related to question : {query} Do not remove necessary information related to context. Consider `\n` as newline character."
# Filling the template with the actual context and question.
filled_template = Template.format(context=context, question=query)
#pip install groq
import os
from groq import Groq
client = Groq(
api_key=groq_api_key ,
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": filled_template,
}
],
model="mixtral-8x7b-32768",
)
print(chat_completion.choices[0].message.content)
YouTube Tutorial Video